


Innovations Leading up to DeepSeek R1
To fully appreciate DeepSeek R1’s capabilities, it is important to understand the evolution of DeepSeek’s models and how each step led to the development of this advanced reasoning model.

In this session, we explored the architecture evolution and technical innovations that led to development of DeepSeek R1, a model that stands at the forefront of AI advancements. DeepSeek R1 pushes the boundaries of reasoning in artificial intelligence and is designed to handle efficiency, lower cost, and cutting-edge performance. To fully appreciate DeepSeek R1’s capabilities, it is important to understand the evolution of DeepSeek’s models and how each step led to the development of this advanced reasoning model.
Technical Evolution and Foundation
Since its inception in 2023, DeepSeek has continually advanced its large language models (LLMs), with each new release building upon the previous model’s strengths. Below is a detailed breakdown of the contributions made by each iteration, culminating in the creation of DeepSeek R1.
DeepSeek V2
We’ll start with exploring DeepSeek-V2, which was a large language model (LLM) released in May 2024. This model introduced significant architectural advancements, notably the integration of multi-head latent attention (MLA) and a mixture of experts (MoE) framework. The MLA mechanism enhanced the model’s ability to process complex patterns by utilizing compressed latent vectors, thereby improving performance and reducing memory usage during inference. The MoE architecture allowed the model to activate a subset of specialized experts per forward pass, optimizing computational efficiency.
DeepSeek-V2 was trained on an extensive dataset of 8.1 trillion tokens, with a higher proportion of Chinese text compared to English. The context length was extended from 4,000 to 128,000 tokens using the YaRN method, which improved the model’s ability to handle longer sequences. The training process involved supervised fine-tuning (SFT) on 1.5 million instances for helpfulness and 300,000 for safety, followed by reinforcement learning (RL) using Group Relative Policy Optimization (GRPO) in two stages: one focused on math and coding problems, and the other on helpfulness, safety, and rule adherence.
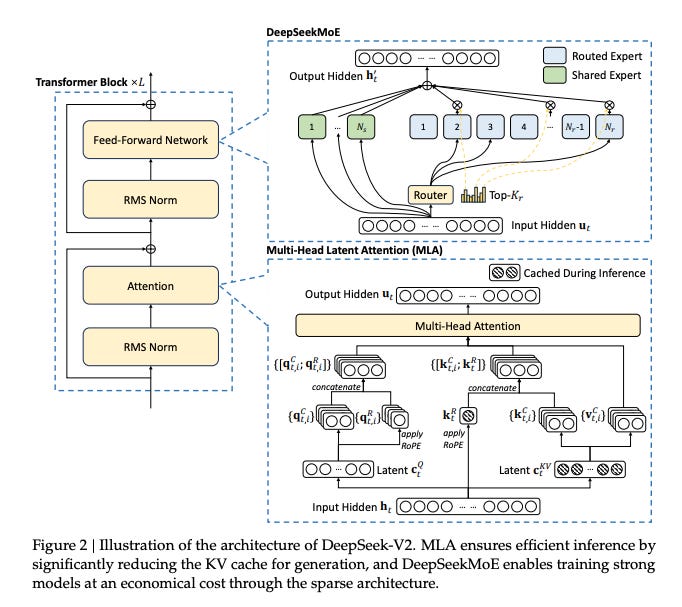
Source: DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek V3
Building upon the V2 architecture, DeepSeek introduced V3 in December 2024. This iteration maintained the MoE framework and MLA, featuring a total of 671 billion parameters with a context length of 128,000 tokens. The training process for V3 involved pretraining on 14.8 trillion tokens, predominantly in English and Chinese, with a higher ratio of math and programming content. The context length was further extended from 4,000 to 128,000 tokens using YaRN.
SFT was conducted for two epochs on 1.5 million samples of reasoning and non-reasoning data. Expert models were trained to generate synthetic reasoning data in specific domains (math, programming, logic), and model-based reward models were developed to guide the RL process. The final model, DeepSeek-V3, was trained using GRPO with both reward models and rule-based rewards. This version marked a significant step forward in computational efficiency and reasoning capabilities, ensuring that the model could better handle complex tasks and improve its overall performance.
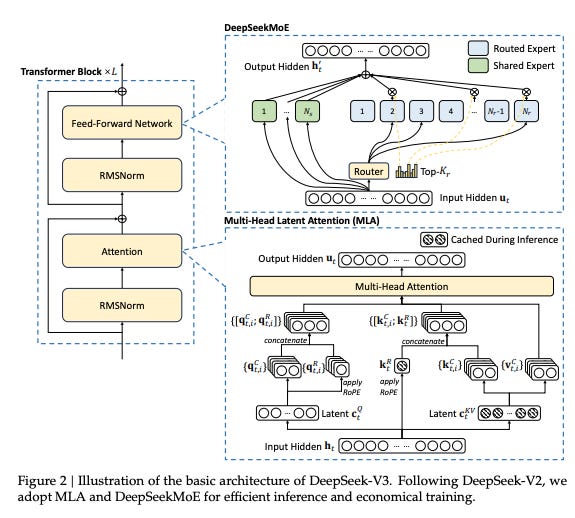
Source: DeepSeek-V3 Technical Report
DeepSeek R1-Zero
In November 2024, DeepSeek released R1-Lite-Preview, an early version of R1, accessible via API and chat interfaces. This model was trained for logical inference, mathematical reasoning, and real-time problem-solving. It was reported to outperform OpenAI’s o1 model on benchmarks such as the American Invitational Mathematics Examination (AIME) and MATH.
R1-Lite-Preview was initialized from DeepSeek-V3-Base and shared its architecture. The model employed a Mixture of Experts (MoE) framework with 671 billion parameters, activating 37 billion per forward pass to maintain computational efficiency. The training process for R1-Lite-Preview involved supervised fine-tuning (SFT) on a small dataset of high-quality, readable reasoning examples, followed by reinforcement learning (RL) to further develop its reasoning skills. This approach encouraged the autonomous emergence of behaviors such as chain-of-thought reasoning, self-verification, and error correction, setting the foundation for the more advanced R1 model.
DeepSeek R1
On January 20, 2025, DeepSeek launched R1, an open-source AI model emphasizing reasoning capabilities. R1 was initialized from DeepSeek-V3-Base and shares its architecture, including the MoE framework with 671 billion parameters, activating 37 billion per forward pass to maintain computational efficiency. The training process for R1 involved a four-phase pipeline:
Cold Start: Supervised fine-tuning on a small dataset of high-quality, readable reasoning examples.
Reasoning-Oriented RL: Large-scale RL focusing on rule-based evaluation tasks, incentivizing accurate and coherent responses.
Supervised Fine-Tuning: Synthesis of reasoning data using rejection sampling, combined with non-reasoning data for comprehensive fine-tuning.
RL for All Scenarios: A second RL phase refining the model’s helpfulness and harmlessness while preserving advanced reasoning skills.
This approach led to the emergence of complex reasoning patterns, such as self-verification and reflection, without explicit programming. Distilled versions of R1, ranging from 1.5 billion to 70 billion parameters, were also developed to cater to different computational needs. R1’s focus on improving reasoning and inference abilities while maintaining computational efficiency marked a key advancement in the evolution of DeepSeek’s models.
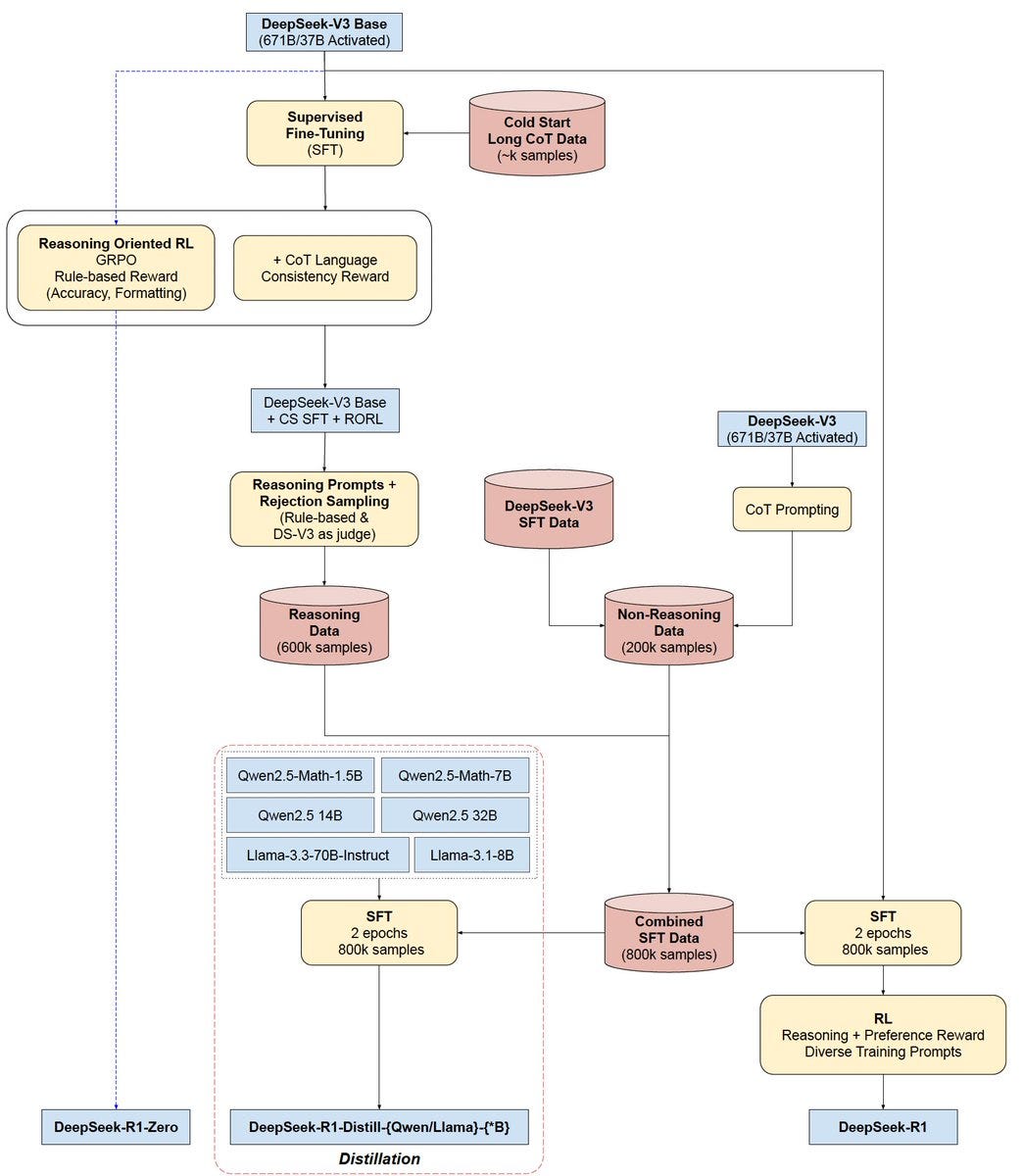
Source: DeepSeek R1 architecture by @SirrahChan
Multi-Token Prediction Innovation
One of the most significant advancements in DeepSeek R1 is its novel approach to multi-token prediction, which enhances both the depth and flexibility of the model’s output.
Sequential Prediction Modules: Traditional AI models often rely on parallel token prediction, generating multiple tokens simultaneously. In contrast, R1 adopts sequential prediction, where tokens are generated one after another in a stepwise manner. This method improves contextual relevance and coherence, as each token’s prediction is informed by the ones that came before it, leading to more cohesive and meaningful output.
Enhanced Internal Representations: The switch to sequential prediction allows R1 to develop richer internal representations of data. This change improves the model’s planning capabilities and enhances its ability to capture long-term dependencies in the sequence, which is crucial for tasks involving complex logic or narrative structures.
Densified Training Signals: In traditional training setups, models predict a single token at a time, which limits the amount of useful training feedback per step. R1’s approach of multi-token prediction increases the density of training signals per step, providing more concentrated and effective learning, which contributes to its superior accuracy.
Shared Embedding Layers: By utilizing shared embedding layers in combination with sequential transformer blocks, R1 achieves better cohesion between tokens in a sequence. This improves the consistency of predictions across different tokens and helps the model generate more coherent outputs overall
Data Processing and Quality Control
DeepSeek R1’s performance is not just driven by its architecture but also by its innovative approach to managing and processing data, ensuring both efficiency and high-quality outputs.
Cross-Dump Deduplication: R1 implements cross-dump deduplication across 91 instances of Common Crawl data, eliminating redundant or repetitive entries. This ensures that the model is exposed to a broader range of unique, high-quality data during training, which enriches its understanding and generalization capabilities.
Strategic Exclusion of Multiple-Choice Questions: Unlike many other pre-training models that include multiple-choice questions, R1 excludes them. This strategic decision allows the model to focus on more complex language tasks that require deeper understanding and nuanced responses, enhancing its ability to process subtler forms of reasoning.
Mathematical Content Enhancement: R1 incorporates an iterative classification approach to enhance the mathematical content within its training data. This process strengthens its ability to process and reason through mathematical concepts, improving its performance in specialized tasks that require advanced mathematical reasoning.
Innovative Bin Packing Algorithms: To address the common issue of document truncation, R1 employs innovative bin packing algorithms. These algorithms optimize the organization of training data, reducing unnecessary loss of information and ensuring that the model has access to as much data as possible to predict the next token.
Practical Applications and Implementation
For those looking to implement R1, its practical applications are key to understanding its capabilities and maximizing its potential.
Best Suited for Verifiable Tasks: R1 is particularly well-suited for environments where success criteria are clearly defined and verifiable. This makes it an ideal choice for industries that require transparency, accountability, and high levels of precision, such as healthcare, law, and finance.
Different Prompting Strategies: Unlike traditional models that often rely on standard prompting strategies, R1 requires experimentation to determine the most effective prompting techniques. This flexibility allows for tailored interactions, enabling users to unlock the model’s full potential across a variety of applications.
Trajectory Planning in Agent-Based Systems: R1 performs exceptionally well in trajectory planning tasks, where it predicts the best possible path forward for an agent navigating dynamic environments. This ability makes R1 a valuable tool for agentic workflows.
Future Implications and Research Directions
As DeepSeek R1 continues to evolve, several exciting avenues for future research and improvement are emerging:
Optimal Stopping Criteria for Reasoning Chains: Research into the best points at which reasoning chains should be terminated could significantly optimize both performance and efficiency, preventing unnecessary computation while ensuring high-quality outputs.
Cross-Lingual Reasoning Capabilities: R1’s performance across languages, particularly in reasoning tasks, suggests a promising area for further exploration. Optimizing R1 for cross-lingual reasoning could expand its applicability to multilingual environments, broadening its scope in global applications.
Token Distribution Impact on Reasoning: Investigating how varying token distribution strategies influence reasoning quality could provide valuable insights into further optimizing R1 for different types of reasoning tasks, from simple queries to complex, multi-step deductions.
Integration with Existing Agent Frameworks: A key research direction is how R1 can be integrated with existing agent frameworks. This could enhance its ability to make autonomous decisions in real-world applications, further extending its utility in dynamic and interactive environments.
By understanding these technical foundations and innovations, we can better leverage DeepSeek R1’s capabilities while acknowledging areas for future development and optimization. Through thoughtful implementation and ongoing research, DeepSeek R1 holds immense potential to drive forward the field of artificial intelligence reasoning.
Resources
To Code, or Not To Code? Exploring Impact of Code in Pre-training
Better & Faster Large Language Models via Multi-token Prediction
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
DeepSeek LLM Scaling Open-Source Language Models with Longtermism
DeepSeek-Coder: When the Large Language Model Meets Programming - The Rise of Code Intelligence
FAQ
Q: What are the primary innovations leading up to DeepSeek R1?
A: Multi-head Latent Attention (MLA)
⦿ What it is: Enhances attention mechanisms by working on latent representations instead of raw token sequences, improving efficiency and scalability.
⦿ Prior work: Perceiver (DeepMind, 2021) introduced attention over latent variables, reducing quadratic complexity in long-context scenarios.
⦿ Why it matters: Helps with long-context processing by operating on compressed representations, enabling better retrieval and reasoning.
Load Balancing for MoE Models
⦿ What it is: Ensures even distribution of workload across experts in Mixture of Experts (MoE) models, preventing bottlenecks.
⦿ Prior work: GLaM (Google, 2021) improved expert selection using an auxiliary routing loss, optimizing compute efficiency.
⦿ Why it matters: Makes MoE models more efficient and scalable, allowing better utilization of compute resources while maintaining high performance.
Fill-in-the-Middle (FIM) Learning Objective
⦿ What it is: Trains models to generate missing text segments, not just predict the next token, improving bidirectional reasoning.
⦿ Prior work: Codex (OpenAI, 2021) leveraged FIM to enhance code completion, significantly improving edit and autocomplete capabilities.
⦿ Why it matters: Enables better document completion, code generation, and interactive AI assistants that can modify text instead of just appending to it.
FP8 Training (Floating Point 8-bit Precision)
⦿ What it is: Uses lower-precision floating-point formats to reduce memory usage and accelerate training.
⦿ Prior work: NVIDIA Hopper Architecture (2022) introduced hardware-optimized FP8 support, enabling more efficient training of large models.
⦿ Why it matters: Reduces training costs and memory constraints, making long-context and large-scale models more feasible.
Multi-token Prediction
⦿ What it is: Instead of generating tokens one at a time, the model predicts multiple tokens in parallel, improving response fluency and speed.
⦿ Prior work: PaLM 2 (Google, 2023) refined parallel decoding techniques to improve latency and coherence in text generation.
⦿ Why it matters: Reduces response time and improves fluency in long-form text generation, making AI models more usable in real-time applications.
Q: How does the use of multi token prediction in R1 improve context and coherence compared to traditional models?
A: In non-reasoning models, the next token is predicted individually at each step, which can sometimes lead to a lack of context or coherence in longer sequences. R1’s approach of predicting multiple tokens allows for a richer internal representation, which helps in planning and reasoning. Although these multi-token prediction modules are removed during inference, the richer training signals learned during the process contribute to more accurate token distributions and better reasoning, ensuring that R1 maintains context and coherence when generating responses.
Q: How did the inclusion of mathematical and coding tokens during training enhance R1’s reasoning abilities?
A: R1 benefited from a large set of math tokens, which were gathered through a process that involved using open web math as a seed, followed by applying a classifier to identify math-related documents in common crawl data. This methodology enabled R1 to acquire 120 billion math tokens, which were important for improving the model’s mathematical reasoning abilities. Additionally, the model’s ability to handle code was enhanced by a pre-processing pipeline that ensured proper ordering of files, including dependencies. Learning from more structured and verifiable domains like math and coding helped R1 learn the mechanics of reasoning which was generalized to other types of reasoning through training.
Q: How does DeepSeek R1 handle model bias?
A: All models have bias and their creators take steps to mitigate that. One of the observations I (Suhas) made during testing is that the model performed better when reasoning in Mandarin compared to English, especially for tasks requiring logical reasoning. This improvement seems to be related to the higher Shannon entropy of the Chinese alphabet (9.56 bits per character) compared to the English alphabet (3.9 bits), which may allow for richer token distributions and more efficient encoding of information. In terms of mitigating bias, the model seems to respond well to diverse inputs, and further research is ongoing to test how language and token distribution affect reasoning capabilities.
Q: What are the primary evaluation metrics and testing strategies for assessing the performance of new AI models like R1?
A: When evaluating new models like R1, I (Suhas) use a variety of strategies to assess reasoning capabilities. One method is to take potentially familiar data from the model’s pre-training and alter it in such a way that it challenges the model to demonstrate whether it is merely recalling information or engaging in actual reasoning. For instance, I may jumble parts of the prompt to see if the model can still generate a correct answer based on the modified context. Additionally, I break complex tasks into smaller sub-tasks to evaluate whether the model can handle these individual components. If the model performs well on each sub-task independently, it provides insight into whether it can successfully tackle the full, multi-step task. This helps assess both the model’s ability to memorize and its capacity for generalizing reasoning across different problem types.
Q: Can DeepSeek R1 be effectively used in agentic applications, where reasoning and planning are required, and if so, how?
A: Yes. One of its strengths is the ability to sample from a set of potential actions, using heuristics to guide decision-making in agentic trajectories. Even without explicit support for tool calls, the model performs well when tasked with reasoning and planning. In my experience, I (Suhas) have tested the model by providing specific tokens in the prompt, which act as delineators, helping the model to follow a structured reasoning path. This approach has shown promising results, demonstrating the model’s potential for handling tasks involving reasoning and planning.
ACKNOWLEDGEMENT: These notes are prepared by Mohsin Iqbal.