
How to do retrieval augmented generation (RAG) right!
My client: “hey, we have this vector db + LLM RAG thing and it’s not working”. And my answer is often “pull in the chair and sit down, we need to talk about how robust software is built".

Why write this article?
Well, it’s no surprise that retrieval augmented generation (RAG) has become such a commonplace paradigm for all things LLMs these days. I would attribute that to two things: 1) it’s pretty straightforward to understand and implement 2) vector db vendors are making damn sure you “think” RAG (with their product) is all you need to live happily ever after. Really, though?
That’s why a lot of my client conversations start by “hey, we have this vector db + LLM RAG thing and it’s not working, do you know why”. And my answer is often “pull in the chair and sit down, we’re going to have a long chat about how robust software is designed and built”.
The reality is, a one-size-fits-all approach just doesn't work when it comes to information retrieval, data handling, and reliable language generation. It all starts by thinking deeply about what your software is trying to achieve, what “good” performance means quantitatively, and how that definition of “good” can act as a north star to guide your design and implementation decision.
In order for us to discuss how RAG should be used properly, let’s first recap what the motivation behind it is.
Why RAG though? for real…
Even the most impressive large language models (LLMs) stumble when it comes to verifiable facts, real-world understanding, and staying grounded in anything, esp. when it comes to the sparse parts of the data they were trained on. Besides that, as the name suggests, they are language models which means that they are only reliably good at parroting the average language used on the internet, and not the other 1000 things we would like to do with them.
But what if we could connect these powerful language models to up-to-date, trusted, and authoritative external knowledge sources such as databases, APIs, proprietary documents, knowledge graphs, you name it? Imagine a chatbot that can draw upon a company's vast knowledge base, customer interaction history, and product documentation to provide truly personalized and effective customer support. These possibilities highlight the desirability of such interfaces: expanded capabilities, richer understanding, and more nuanced responses.
RAG was proposed as a way of retrieving targeted, relevant information from external data sources to enrich the responses of language models. RAG provides the opportunity to have granular control over the behavior of the LLM by separating the linguistic interface (LLM itself) and the data layer. This allows for a more modular approach where all the appropriate processing can happen at the data layer (eg. measures for security, privacy, access control, relevance, refinement, guardrails) and let the LLM be in charge of what it’s good at: understand what the user is saying, and respond elegantly.
The Need for External Data Integration
Large language models trained on existing data are inherently limited in major ways:
Limited Knowledge and Expertise Scope: No matter how much data is ingested during training, these models can't cover the full breadth of factual knowledge about our infinitely complex world. There will always be gaps to be filled. This is compounded by the fact that LLMs are trained to be good at language skills which does not make them great at other expert tasks like mathematics, analyzing structured data, or simulating the physical world.
Factual Inaccuracy and Hallucinations: Given that they are only trained to predict the next most likely token, language models can easily generate information that is outdated or plain wrong. They operate based on patterns in the text data, without a deep understanding of how the information connects to real-world entities, events, and concepts. They sometimes produce fluent yet false information (hallucinations) as they try to "make sense" of sparse data, leading to spurious correlations.
Inconsistency: Language models can produce different results from run to run, even with the same inputs, due to their probabilistic nature and lack of explicit design for deterministic outputs. This can be problematic when using LLMs for tasks requiring stable and reproducible results, such as in scientific, financial, or legal contexts. For example, an LLM might incorrectly state a historical date or generate conflicting legal interpretations for the same query across multiple runs.
Integrating external data sources through RAG can help address these limitations by coupling them with more reliable information retrieval systems. It is also important to recognize the pertinent challenges involved, including seamlessly interfacing diverse data formats, balancing retrieval quality and efficiency, and ensuring the external data is trustworthy and up-to-date. If we can get it right, RAG has the potential to unlock a new level of knowledge-intensive, contextually aware interactions across a wide range of domains, which we will explore further at the end.
Validation Driven Development
We said earlier that the one-size-fits-all approach to interfacing LLMs with external data, as suggested in vendor blog posts online, does not work. Instead the architecture used has to be tightly designed around the nuances of the workflow it’s expected to augment. Humans don't simply regurgitate memorized facts. We gather information, analyze it, and then use language to communicate our understanding. RAG that mimics this process can be more nuanced and adaptable. Imagine a system that can not only retrieve relevant information but also identify potential biases or missing context, just like a human researcher might. This would lead to more reliable, nuanced, and insightful outputs.
Don’t get me wrong! A basic RAG architecture might be a good starting point, but it's crucial to assess its performance across diverse situations to deeply understand where it stumbles. Does it struggle with factual queries or with keeping consistent themes in creative writing tasks? Identifying these weaknesses allows us to be targeted and efficient with potential improvements. By pinpointing the common patterns of error coming out of a thorough assessment of a simpler, starter architecture, we can explore ways to enhance the system’s capabilities.
The landscape of potential improvements can be overwhelming. Should we try a different LLM? Should we increase the size of the database? Tweak the retrieval algorithm? Fine-tune the model? Trying to tackle everything at once is a recipe for wasted effort. Instead, focusing on the most important shortcomings in performance, one at a time, allows for a more systematic approach. We can identify a specific weakness, test targeted solutions, and measure the impact. For example, imagine systematically addressing the system's tendency to generate factual inaccuracies. By iteratively improving the fact-checking capabilities, we can build a more trustworthy and reliable RAG system.
Validation vs Evaluation vs Verification
Evaluating LLM-based software, often used to tackle various cognitive use cases within a certain business context, presents a unique challenge compared to traditional software or even less advanced ML models. While the core principles of verification, validation, and evaluation still hold true, their application requires adaptation to the dynamic nature of LLMs.
Before getting into the details of each of these terms, let’s define what we mean by these terms:
Evaluation: Is the software good? Eg. Is the system good at doing math?
Verification: Is the software built right? Eg. Did this iteration of the system run provide the correct math answer?
Validation: Is the software built, the right thing? Eg. is the LLM system good at the math questions the user cares about?
Evaluation, assessing the overall quality and impact of the LLM system, is not always trivial. Traditional metrics like accuracy may not fully capture the nuances of human language interactions. New metrics encompassing factors like fairness, interpretability, and creativity are needed to judge the system’s effectiveness. It is often also helpful to take a step back and look at the impact of the output of the system on a measurable downstream task (eg. did the generated proposals result in more sales). Evaluation needs to be ongoing and iterative, monitoring for potential drift in performance or the emergence of unintended biases as the models, esp. third party ones, evolve.
Verification, ensuring the system functions as designed every time, becomes more nuanced. Traditional unit testing struggles to capture the emergent behavior arising from complex interactions between LLM components. Instead, techniques like adversarial testing (red teaming), fuzzing (stress testing by feeding unexpected data), and testing individual details of the output (eg. numbers, entities, fact checking) are crucial to uncover unexpected outputs and biases:
Returns an invalid json
Returns a schema not consistent with your prompt
Your prompt (part of Intellectual Property) gets leaked
Replies with harmful content like hate speech
Produces malicious code
Jailbreaks your prompt
Function calling returns incorrect signature
Validation, confirming the LLM meets user needs, takes on a new dimension. The stochastic nature of the output makes it difficult to decide if an output is reliably good. Besides, in many situations it is hard to decide if a certain output, say a few paragraph text with lots of technical details, is objectively acceptable. Finally, the opaque nature of LLMs makes it difficult to understand their reasoning and decision-making processes. Thinking carefully about the user experience of the overall system is an important ingredient for gaining the user’s trust. This might include verbosely showing the process the system is executing to keep the user engaged, or showing citations for information presented, or communicating the results of verifications if warnings are needed.

So, here's the recipe:
Before writing any code, wrap your head around how evaluation, validation, and verification will happen throughout the development process and procure the necessary data for this.
Implement comprehensive guardrails to prevent undesirable outcomes.
Leverage a metric-driven development approach to tailor evaluations to specific use cases.
Utilize formal verification when necessary to ensure the reliability and safety of LLMs.
Modular RAG
Let’s recap! The basic architecture my vector db provider tells me to use doesn't work. I have to spend a lot of time wrapping my head around what “good” means for my use case and what data should be used to measure it. And also there’s no clear path between the basic architecture and what’s needed to get to the promised “good” performance. Got it!
Well, software engineering 101 says: in a situation like this, make the architecture as modular as you meaningfully can so that you can move things around or swap things in and out, and experiment extensively to find the right combination.
Now, let’s introduce “modular RAG”, aka a properly engineered software system inspired by RAG.
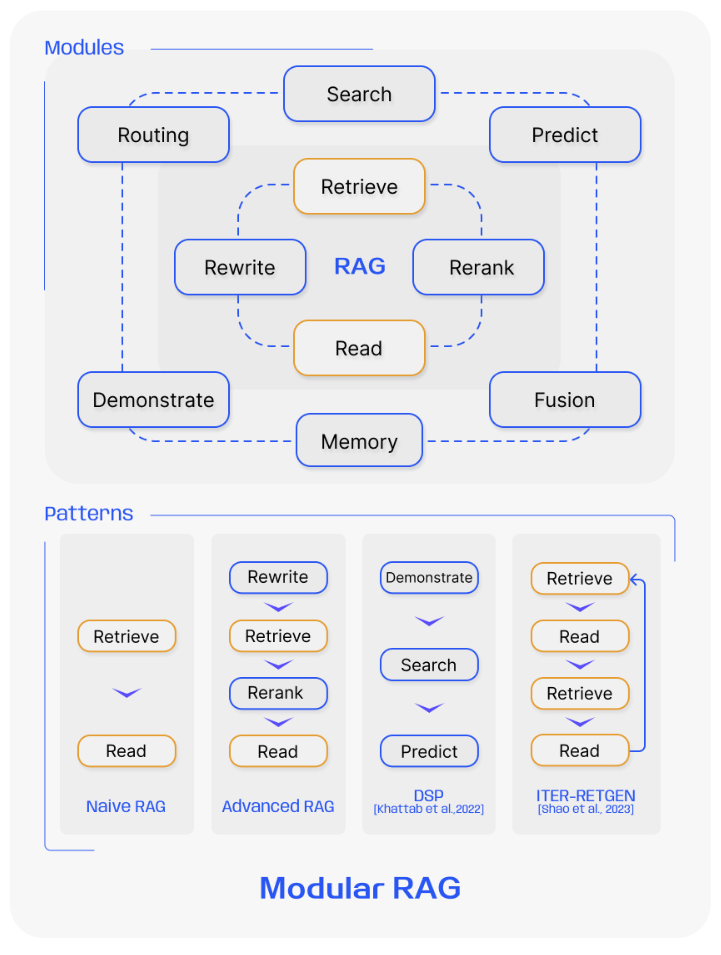
Common modules
Of course, in reality, the modules will end up largely replicating the steps a human would take to carry out a particular workflow. So, it’s generally good practice to deeply understand the workflows, standard operating procedures, that humans follow, break them down into sub-tasks, and design your architecture to replicate that. Chances are you won’t get it right the first time, second, or n-th time because humans do a lot of sub-tasks that they don’t consciously realize they do. But at least you have a modular setup that you can modify based on the edge cases you are uncovering in each iteration.
That said, there are modules that are relatively common for various use cases. Let’s take a look at them.
Query Expansion and Rewriting
This first module involves transforming the user’s query or prompt into a format optimized for searching the external knowledge base or data source. This often involves rephrasing the query, identifying keywords, or explicitly adding relevant info that is implicit in the user’s utterance. More sophisticated methods can turn the query into a rich "search object" containing search phrases, database filter values, query type classifiers, and other metadata to properly configure the subsequent retrieval stages.

Query expansion has been used for decades to bridge the vocabulary gap between how users express queries and how information is stated in databases. For example, one classic approach is pseudo-relevance feedback, which retrieves documents based on the initial query, identifies keywords from those documents, adds them to the original query, and retrieves them again.
In the world of LLMs, there are several techniques:
Hypothetical Document Embeddings (HyDE) creates a hypothetical document relevant to the query, uses its embedding to retrieve nearest neighbor documents, and rephrases the query into better-matched terms.
Step-Back prompting allows large language models (LLMs) to perform abstract reasoning and retrieval based on high-level concepts.
Query2Doc creates multiple pseudo-documents using prompts from LLMs and merges them with the original query to form a new expanded query.
ITER-RETGEN proposes a method that combines the outcome of the previous generation with the prior query. This is followed by retrieving relevant documents and generating new results. This process is repeated multiple times to achieve the final result.
For a more in-depth exploration of these query rewriting techniques, please refer to this article.
For overall pipeline efficiency, it is crucial to balance the complexity and compute requirements of query expansion. While large language models like GPT-4 are capable of handling query expansion and rewriting, they are often too computationally expensive and slow for efficient use in production settings. To achieve a better balance between performance and efficiency, alternative methods can be employed. Using task-specific fine-tuned small LLMs, knowledge distillation, or even methods like pseudo-relevance feedback (PRF) can provide good performance at a lower cost. In some cases even very small classifiers trained on high quality data can make a big difference in explicitly telling the system what to look for.
Information / Example Retrieval
With the user's query rewritten into an optimized search object, the Retrieve module fetches potentially relevant information from external data sources. This could involve keyword searching over a set of documents, extracting specific passages, querying structured databases via APIs, or even writing SQL-type queries. This could also involve a mixture of all of the above, and even calling other expert models (machine learning or statistical models or even physics/engineering simulations) served via APIs.
Another type of subtask a module like this might do is finding relevant examples (eg. FAQ) and putting them into the context of the eventual LLM call for a few-shot setup. This can significantly improve the repeatability of the output from the overall setup by showing examples of how similar problems were handled in the past.
Reranking & Post-processing
The goal of retrieval is to grab as much potentially relevant information as possible, even if some of it ends up being irrelevant. Some of these results might already be ranked within the assumptions of their respective systems and search parameters sent to them. However, those rankings might not be relevant to the query at hand.
After retrieving a large pool of relevant document chunks or data points, the reranking stage plays a crucial role in determining which set of chunks or data points are most relevant to the user’s query. This is a critical step because the language model can only process and utilize a limited context to produce the correct answer.
In most baseline implementations, reranking could be done using simple semantic ranking. However, more advanced relevance scoring techniques, such as cross-encoders, query likelihood models, or other supervised ranking models, can be employed to improve the accuracy of the reranking process. By using these methods, the reranking stage assigns higher scores to the most pertinent information and lower scores to less relevant or irrelevant data. This helps prioritize and select the most valuable content that will assist the LLM in providing a correct response to the user's query.
One word of caution here is the following: It is tempting to jam as much info in the context window of the LLM as possible and hope that the LLM attention mechanism can robustly tell what’s relevant. This doesn’t necessarily hold esp for very long prompts (see Lost-in-the-middle problem). So while part of the reason that we do this re-ranking is to cut off irrelevant information, another reason for it is that we can use the score to try a few different arrangements of the information in the prompt. You might end up finding that putting the most relevant info at the bottom is better, or alternating between top and bottom, or any other arrangement.

At this point, we have retrieved and selected the most relevant texts that can potentially serve as input to the LLM. However, we must ensure that the retrieved information is free of any irrelevant, redundant, or lengthy texts and it fits well within the context limit of the LLM. To achieve this we can post-process the chunks or data. For textual data we can employ two primary methods: summarization and chain-of-note generation. For other types of data the post-processing might involve doing math on the retrieved info or any other specialized operation that boils down the data to what is strictly needed for the task at hand.
Prompt Crafting and Generation
Once the content to be fed to the LLM has been determined through the previous modules (documents, summaries, notes, processed data, examples), the next step is to decide how to present this information to the LLM. The way the content is structured and fed into the LLM can significantly impact the quality and coherence of the generated responses.
There is not a whole lot of science here (definitely not engineering as much as people like to think “prompt engineering” is “engineering”). But the good news is that you have all the pieces of information (instructions, examples, retrieved and processed data) in separate data elements, so you can try various data templates and order of the info until it gives you the desired output.
Finally, the crafted prompt is fed into the LLM, which processes this context and produces a final response to the user's query. The standard approach is to generate the output all at once, but more advanced techniques involve interleaving generation and retrieval in an iterative process called active retrieval or generating multiple outputs and selecting the best.
Active retrieval generates some output, retrieves more context based on the generated text, and then generates more output, iterating until a complete response is formed. This can help maintain coherence in long-form text generation. The decision to retrieve additional context can be based on various factors, such as a fixed number of tokens generated, completion of textual units like sentences or paragraphs, or when the available context is deemed insufficient to continue generating a meaningful response.

Verification
If you think that you have generated a response and you’re done, I’m sorry to tell you that you are not. At this stage you did all you could to feed the LLM the right info, but what it has done with it is unpredictable and more often than not, it might hallucinate or get the details wrong. That’s why it is important to include some modules that verify the details of the output. This could include checking that entities and numbers mentioned are actually present in the context you provided. Or fact checking the generated response sentences against the chunks passed to the LLM. This could get as elaborate as doing linguistic analysis on the output to check if it meets certain requirements.
What you do in case of “pass” or “fail” of these verifications depends on the use case and the severity of the issue. Sometimes it might be just appropriate to append a warning to the user. Sometimes you might provide the failure along with some additional info as feedback to the LLM, asking it to try again. Sometimes you could overlay the verified information (eg. fact checking results) as citations inline with the generated text. Sometimes you might have a more elaborate policy about how different verifications should be done and how the system should behave depending on the outcome.
Design patterns
There aren’t many well established patterns for how these modules might come together to build your pipeline. The ones discussed above are most probably going to show up in the order presented here. You can see some of the ones presented in various academic papers in the image presented at the beginning of this section.
Ultimately though, as mentioned previously, the pattern you follow will have to replicate the cognitive process and the business workflow you are integrating into. Once you get deep enough in the weeds of those workflows, it’s likely to realize that a human executing the cognitive process makes decisions about taking different sets of steps based on previously available information. This often leads you into creating routing modules that replicate that decision process with pre-determined configurations of modules in each of the possible decision pathways, making it almost like it has “agency”!
RAG and Agentic Workflows
It is common to also realize that different configurations of the modules are necessary for different types of scenarios your system needs to handle. Of course, we all wish that we had more autonomous agents to handle all this for us. But in the foreseeable future, what people call “agentic workflows” is most often routing or configuration selecting modules that robustly select the right pipeline to handle the variance in the user queries.
What constitutes an “agent” and what that implies are beyond the scope of this write up and will be dealt with in a future one. Semantics aside, the goal is still to follow the validation driven development, tackling one performance issue at a time. At some point, you have added all the necessary modules but are still struggling with performance and that’s where fine-tuning comes in!
Fine-tuned RAG
Another advantage of the modularity is that each module could be its own independent small model (language or otherwise) fine-tuned or trained to handle the subtasks in the best possible way. For example the router could be a simple query classifier that selects the right pipeline based on the last few interactions with the user. Or retrieval and re-ranking modules can be models trained specifically for handling the types of queries at hand and the nuances of relevance based on annotated ranking data. The prompt crafting stage could also be a model trained in a supervised fashion on pairs of input data and desired output LLM generation (see RLPrompt).
Conclusion
While a basic vector database and LLM combo might seem like a quick win for RAG implementation, it falls short for most real-world use cases. The workflows that RAG aims to augment are inherently complex, demanding more than just finding and summarizing text. This requires additional modules beyond the core RAG architecture.
The key to unlocking RAG's true potential lies in its modularity. By meticulously mapping the specific workflow you're trying to enhance and designing the RAG architecture around its individual steps, you gain immense flexibility. This upfront investment in planning can save significant time, money, and frustration down the line. Remember, validation-driven development is paramount. Start with the simplest possible RAG system, identify its edge cases through rigorous evaluation, and tackle them one by one. By focusing on these core principles, you can build a robust and adaptable RAG system that truly revolutionizes your workflow.
Acknowledgement: This article is inspired by the presentations given by Suhas Pai, Ian Yu, Nikhil Varghese, and Percy Chen. Some of the thought processes presented here are borrowed with permission from the content of Suhas’s book, Designing Large Language Models Applications. The early drafts of this article and the accompanying visuals were provided by Mohsin Iqbal.
Thanks for the article and your speech at AI Practioner event!